
A Developing Developer
웹개발 종합반 (프로그래밍 실무, 풀스택) 39회차 - 파이썬 크롤링 본문
- 크롤링
웹스크래핑이라고도 하는데, 말 그대로 웹페이지에서 필요로하는 데이터를 가져오는 작업이다.
파이썬으로 크롤링 하기위해서는 requests 패키지와 bs4(beautifulsoup4) 패키지 설치가 필요하다.
아래 페이지를 활용해서 크롤링 연습을 해보겠다.
https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829
랭킹 : 네이버 영화
영화, 영화인, 예매, 박스오피스 랭킹 정보 제공
movie.naver.com
- 크롤링 기본 세팅
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829', headers = headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
soup = BeautifulSoup(data.text, 'html.parser')
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
- select / select_one
필요로하는 데이터의 태그를 ' ' 안에 넣어주면 값을 가져올 수 있다.
- 영화 제목 가져오기
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829', headers = headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
soup = BeautifulSoup(data.text, 'html.parser')
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
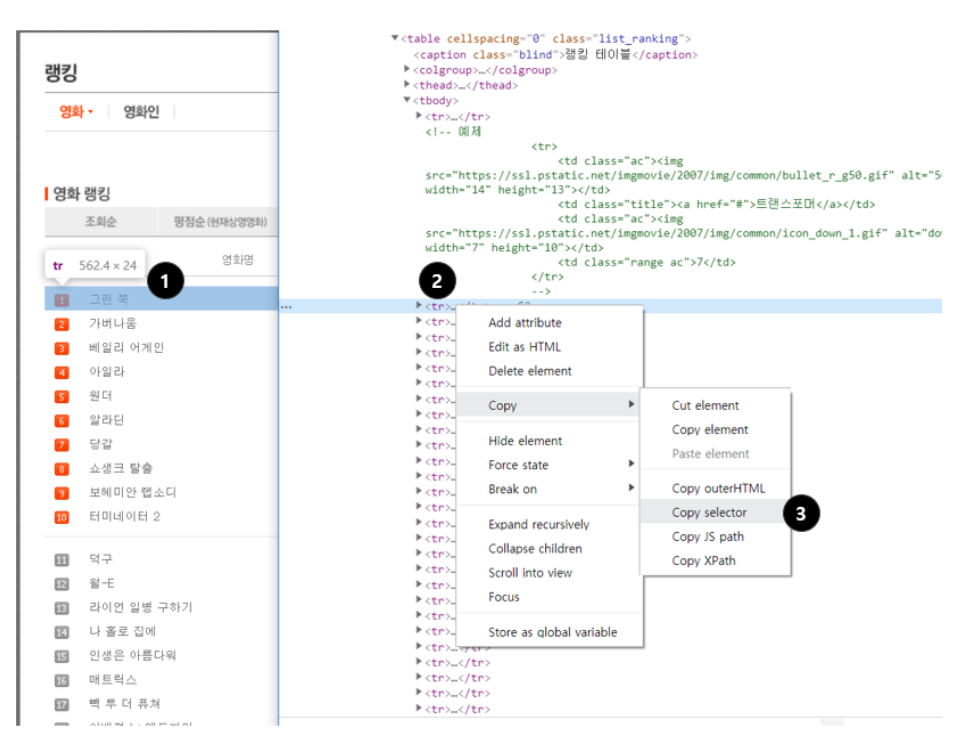
# 개발자도구에서 가져오고자하는 부분을 '검사'해서 필요한 태그를 Copy > Copy selector 로 선택자를 복사 할 수 있다.
movies = soup.select('#old_content > table > tbody > tr') # 가져오고자 하는 데이터의 상위 태그
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a') # 가져오고자 하는 데이터의 태그
if a_tag is not None:
print(a_tag.text)# a의 text를 찍어본다.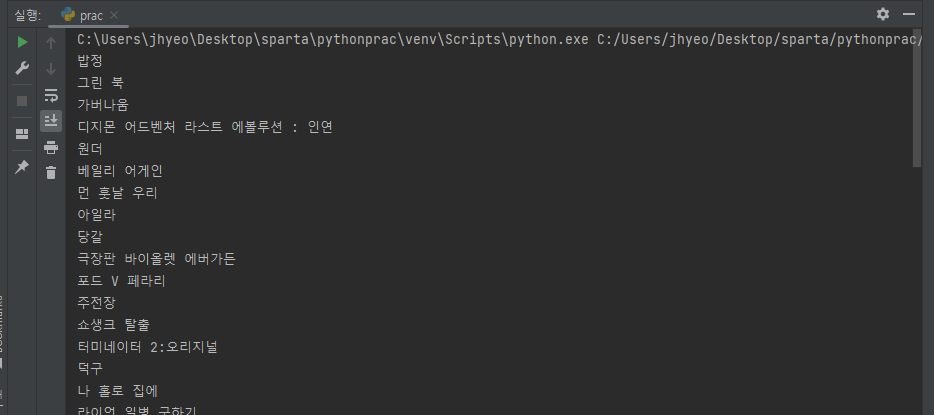
- 랭킹, 제목, 평점 가져오기
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829', headers = headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
soup = BeautifulSoup(data.text, 'html.parser')
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
title = a.text
rank = movie.select_one('td:nth-child(1) > img')['alt']
star = movie.select_one('td.point').text
print(rank, title, star)
=================================================================================
스파르타코딩클럽_웹개발_종합반(강의자료)
=================================================================================
내일배움캠프 4기 사전캠프 7일차이다.
5, 6일차 까지는 배웠던 내용을 복습하는 느낌이였는데. Python 부터는 새로운 내용을 배워서그런지 난이도가 조금 오른거 같다.
6일차의 크롤링을 이어서하고 DB 수업도 있었지만, 시간이 없어서 오늘 수업들은 DB 부터는 내일 개발일지를 작성해야 겠다.
(바쁘다바빠)